È “la scheda acceleratrice più veloce al mondo per l'analisi dati e il calcolo scientifico”. Così Nvidia definisce Tesla K80, una nuova scheda acceleratrice per server dual-Gpu ad altissime prestazioni, destinata all’ambito dell’high performance computing, ad applicazioni di analytics, di machine learning e di calcolo scientifico. Si tratta, in effetti, di una scheda composta da due unità Gpu, che promette prestazioni fino a dieci volte superiori rispetto alle più veloci Cpu attualmente in circolazione.
Simili performance sono frutto dell’eccezionale componentistica: la soluzione si basa infatti su due Gpu GK210, ciascuna dotata di 2496 Cuda core (l’archiettura per il calcolo in parallelo creata da Nvidia), per un totale di 4992 unità. A stupire però sono soprattutto i 24 GB di memoria GDDR5, ovvero il doppio di dei gigabyte presenti sulla precedente scheda Tesla K40, mentre la larghezza di banda arriva a 480 GB/s.
“L’accuratezza necessaria a migliorare i sistemi di deep learning, modelli e database di dimensione sempre maggiore ci spinge a ricercare sempre l'hardware più veloce disponibile”, ha commentato Yann LeCun, analista di AI Research presso Facebook e docente di Computer Science & Neural Science della New York University. “L’acceleratore Tesla K80, con la sua architettura dual-Gpu e l'ampia memoria, ci offre più teraflop e GB che mai in un singolo server, consentendoci di fare progressi più rapidi nel deep learning”.
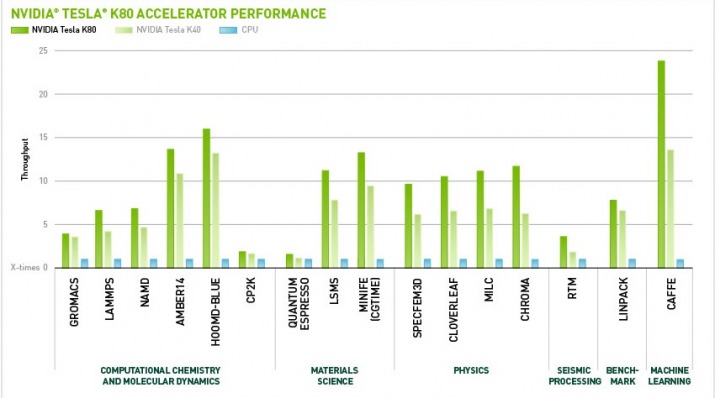
(Dati: Nvidia)
Tesla K80, come analoghe soluzioni di Nvidia, è compatibile con le piattaforme x86, Power 8 e Arm a 64 bit, consentendo quindi modelli di programmazione comuni anche su più Cpu. I primi produttori a utilizzara all’interno di supercomputer saranno Cray, Dell, HP e Quanta.