In un mondo sempre più sommerso dai dati, un alleato strategico per un crescente numero di aziende è Hadoop, il framework open source per l’analisi dei Big Data. Ovvero è il “contenitore” più adatto e flessibile (in quanto open source) per le applicazioni distribuite, che raccolgono e inviano senza sosta i dati di sensori e oggetti connessi. Secondo un’indagine di AtScale (che porta anche la firma di Cloudera, HortonWorks, MapR e Tableau), già lo scorso anno il 76% delle aziende prevedeva di continuare a puntare su Hadoop con nuovi investimenti. Circa una organizzazione su due, inoltre, considerava questa tecnologia come strategica per la propria crescita.
Le motivazioni e i vantaggi all’orizzonte sono spesso chiari, ma molto meno spesso si procede con il metodo e l’approccio corretto. Abbiamo discusso dell’attuale scenario e delle future possibilità di Hadoop con Michele Guglielmo, regional sales director di Cloudera Italia. La software house statunitense propone una distribuzione open source di Apache Hadoop, adatta per implementazioni enterprise.

Michele Guglielmo, regional sales director di Cloudera Itali
Quali tipi di aziende si rivolgono a voi per adottare Cloudera Enterprise?
Vogliamo contribuire alla diffusione del concetto di “enterprise data hub”, nel nostro caso il Cloudera Edh, ossia un unico punto dove raccogliere tutti i dati. Stiamo di fatto collaborando con molte aziende diverse, dalle startup alle grandi imprese locali, per finire con le grandi multinazionali. Lo scorso anno abbiamo assistito a una forte crescita del mercato e con esso anche Cloudera è cresciuta in modo vertiginoso. Oggi contiamo su oltre 1.400 dipendenti e una presenza diretta in più di trenta nazioni.
Dunque non esiste una vera e propria segmentazione del mercato, piuttosto direi che la nostra piattaforma è adottata in modo orizzontale per tipologia di mercato e dimensione aziendale. Di fatto qualsiasi azienda sta cogliendo l’importanza di avere un unico punto dove poter raccogliere qualsiasi dato per poter poi effettuare analisi, correlazioni o migliorare l’operatività dell’It e molto altro nell’ambito della conformità e della sicurezza. Tuttavia non sorprende che le aziende dell’ambito finanziario, delle telecomunicazioni e della Pubblica Amministrazione, cioè quelle che generano il maggior volume di dati, siano particolarmente interessate alla nostra piattaforma per i Big Data.
Da dove nasce il loro interesse?
Le finalità sono davvero moltissime: ogni giorno veniamo a conoscenza di nuovi modi in cui i nostri clienti usano Cloudera, tant’è che il limite è… la fantasia di chi usa la piattaforma. È altrettanto vero che, grazie all’esperienza maturata negli anni, abbiamo capito che la maggioranza dei casi d’uso aziendali si possono ricondurre a quattro filoni principali. Il primo è la modernizzazione dell’architettura It, che viene abilitata a offrire più valore al business con un costo sensibilmente più basso. Il secondo è il miglioramento della conoscenza della clientela, attraverso la creazione di una vista “a 360°” del cliente per generare nuove aree e idee di business. In terzo luogo, si punta ad aumentare l’efficienza di prodotti e servizi, ovvero la capacità di creare prodotti e servizi data-driven e a costi più bassi. Il quarto filone, infine, è la riduzione dei rischi cioè della probabilità di perdite nelle operazioni di business e nell’ambiente in cui l’azienda agisce.
A che punto sono le aziende nel processo trasformazione dei dati in informazioni utili per il business? Quali difficoltà presenta un progetto di questo tipo?
La risposta è intimamente legata a livello di conoscenza del mondo Big Data che ogni singola azienda è riuscita a creare nel tempo. La quantità di dati gestita dalle aziende è davvero grande; così grande che non sempre tutti vengono raccolti, soprattutto perché è impossibile farlo con i sistemi tradizionali e, quindi, spesso non ci si pone nemmeno il problema. Ma le aziende che hanno adottato questa trasformazione ne hanno beneficiato immediatamente in Roi e competitività.
In merito alle possibili difficoltà, è indubbio che un progetto per i Big Data abbia una insita complessità dovuta sia da aspetti architetturali sia di business. Anche in questo caso, l’esperienza ci ha insegnato che partire da una solida base è un fattore discriminante. Per questo motivo affianchiamo i clienti nel loro percorso, lavorando fianco a fianco nello stabilire metriche adeguate a soddisfare gli aspetti It e lo specifico caso d’uso, e certificando tutti gli elementi architetturali necessari per una installazione che abbia rispondenza a necessità di tipo enterprise. Queste necessità che non riguardano solo la raccolta del dato ma anche la sua governance, nel rispetto di tutte le normative e delle policy di sicurezza aziendali. Altro elemento importantissimo è la focalizzazione in pochi casi d’uso che possano portare immediato vantaggio, perché esiste un rischio altissimo di divagare e perdere di vista l’obiettivo primario che ci si era posto.
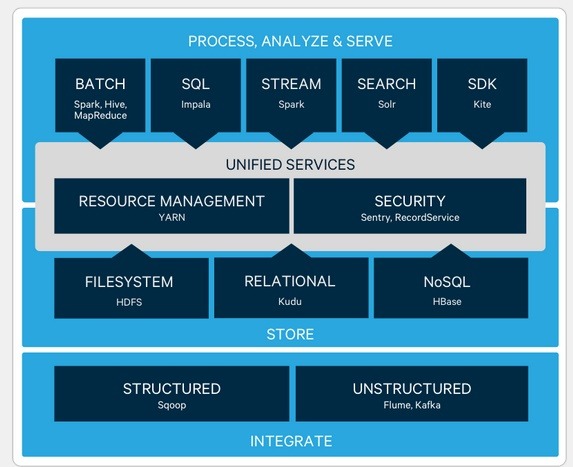
Le funzioni dell'ecosistema Hadoop
Quali errori è facile compiere in un progetto di utilizzo dei Big Data?
Un errore che abbiamo visto ripetersi molte volte è quello di pensare che la trasformazione possa arrivare solo dal mondo It, mentre questi progetti richiedono omogeneità e condivisione. Qualche volta i dipartimenti iniziano sperimentazioni in modo indipendente e con grande passione, ma si scontrano con il fatto che ogni dipartimento accede a una limitata quantità di dati aziendali e, quindi, il progetto naufraga prima ancora di iniziare. Andare oltre il concetto di dati che risiedono su aree separate, i silos, è la base da cui muoversi per avere successo nel mondo dei Big Data. Ed è anche il modo più semplice per le aziende di ottenere immediato valore, visto che i dati sono già presenti ma non ancora disponibili in un unico punto per essere condivisi.
Quali sono le ultime novità presentate da Cloudera e quale la vostra roadmap per il futuro?
Stiamo lavorando su tantissimi fronti e su molte applicazioni e continueremo a farlo. Il nostro nome si sentirà sempre di più in ambito cybersecurity, motivo per cui stiamo sviluppando diversi casi d’uso di successo per la prevenzione di attacchi, di frodi e degli Apt (Advanced Persistant Treath, ndr) in collaborazione con alcune tra le più importanti aziende assicurative a livello mondiale. Nel contempo ci stiamo rafforzando sempre più nell’ambito cloud, dove la nostra piattaforma è disponibile attraverso i più grandi player del settore.
In termini di continua contribuzione al progetto Apache Hadoop, vorrei segnalare una nota particolare sul recentissimo lancio di Apache Kudu, un progetto sviluppato direttamente da Cloudera che ha richiesto grandi investimenti e che sta riscontrando un grandissimo successo. Di fatto Kudu copre un importantissimo gap offrendo una “database-like experience”, cosa che molti clienti lamentavano mancare su Hadoop, abilitando nuovi casi d’uso sulla piattaforma e supportando la crescente domanda di analisi in tempo reale. Così siamo contenti di vedere la comune adozione di Spark tra le distribuzioni di Hadoop e l’allineamento alla visione di Cloudera (per esempio, sul fatto che Spark sia il successore di MapReduce quale motore generale di esecuzione dell’elaborazione dei dati).
Come detto, siamo attivi su tantissimi fronti e molte sono le nuove idee e nuovi stimoli che arrivano dai clienti. Il nostro obiettivo è quello di offrire la migliore piattaforma Hadoop disponibile sul mercato, facile, veloce e sicura, perché – come amiamo dire in Cloudera – nessuno conosce Hadoop come lo conosciamo noi.